Understanding the Microsoft Global Outage Caused by CrowdStrike: A Comprehensive Breakdown
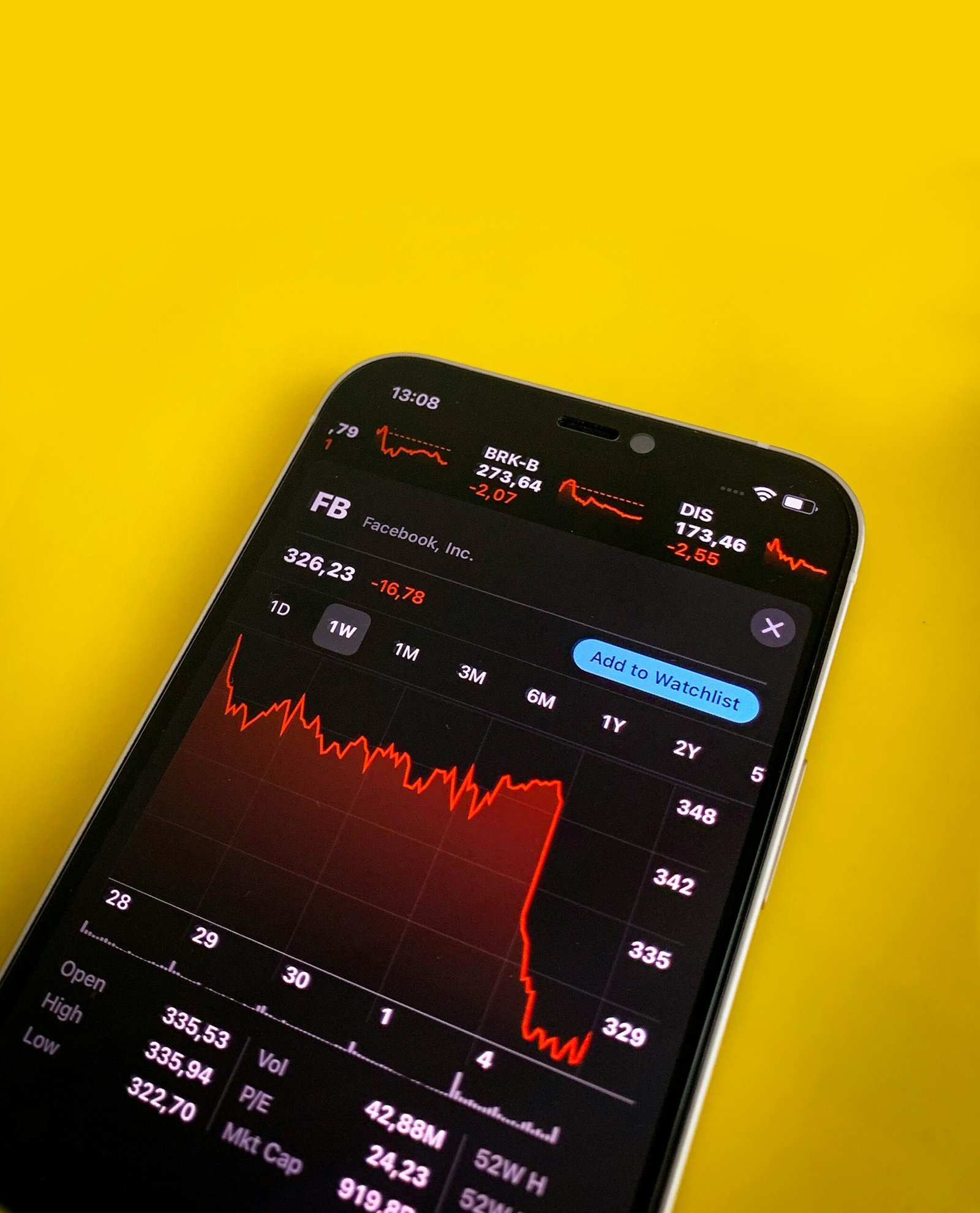
Introduction to the Global Outage
The recent global outage that affected Microsoft services has drawn significant attention from both the tech community and the wider public. This unprecedented event led to widespread disruptions across various sectors, including businesses, educational institutions, and airlines, which rely heavily on Microsoft’s suite of tools such as Azure, Office 365, and Teams. The scale of the outage was such that it paralyzed operations and prompted urgent responses from IT departments worldwide.
At the heart of this incident are two key players: Microsoft, the global technology giant, and CrowdStrike, a leading cybersecurity firm. Understanding the roles these entities played is crucial to comprehending the full scope of the outage. Microsoft’s extensive range of cloud-based services is integral to the daily operations of countless organizations, making any disruption highly impactful. Similarly, CrowdStrike’s reputation as a cybersecurity provider places it at the forefront of investigations into such incidents.
This blog post aims to dissect the events leading up to and following the outage, examining the technical and operational causes behind the disruptions. By doing so, we hope to provide a clear picture of what caused the Microsoft outage and the subsequent steps taken to restore services. The implications of this event extend beyond immediate operational disruptions, highlighting vulnerabilities in cloud service dependencies and the critical importance of robust cybersecurity measures.
As we delve deeper, we will explore the specific sequence of events that culminated in the Microsoft Azure outage, assess the impact on different sectors, and evaluate the response strategies deployed. Through this comprehensive breakdown, we seek to answer pressing questions such as “Is Microsoft down?” and “What caused the Microsoft outage?” while shedding light on the broader ramifications for global digital infrastructure.
What Caused the Outage?
The Microsoft global outage, which disrupted numerous services including Azure, Office 365, and Microsoft Teams, was traced back to specific issues within CrowdStrike’s infrastructure. The incident began with a series of misconfigurations in CrowdStrike’s software deployment systems. These misconfigurations led to the malfunctioning of critical security protocols, which are essential for maintaining the integrity and reliability of interconnected services.
At the heart of the problem was a flawed update in CrowdStrike’s endpoint protection platform. This update inadvertently introduced vulnerabilities that compromised the system’s ability to authenticate and authorize user access. Consequently, this breakdown in security protocols created a cascading effect, impacting Microsoft’s cloud services. Azure, being one of Microsoft’s core cloud services, experienced significant disruptions as its dependency on robust security mechanisms was undermined.
As the issues within CrowdStrike’s platform propagated, they interfered with the normal operations of Microsoft’s authentication services. This interference caused widespread authentication failures, preventing users from accessing their Microsoft accounts and cloud services. The disruption was not isolated to a single region; rather, it affected users globally, highlighting the interconnected nature of modern cloud infrastructures.
The Microsoft outage had far-reaching consequences, notably impacting industries that rely heavily on cloud services, such as airlines and financial institutions. The dependency on Microsoft Azure for critical operations meant that any service interruption had immediate and severe repercussions. In particular, the aviation sector reported numerous flight cancellations and delays due to the inability to access essential scheduling and communication tools.
Efforts to fix the Microsoft outage involved close collaboration between Microsoft and CrowdStrike teams. Identifying and rectifying the root cause required a comprehensive audit of the update processes and security configurations. Once the misconfigurations were corrected, normal service operations gradually resumed, restoring access to affected users worldwide.
Timeline of Events
The Microsoft global outage, which had significant repercussions across various industries, including airlines and numerous businesses relying on Microsoft’s cloud services, began with initial signs of trouble that were first detected in the early hours of the morning. Users across different regions, including India, started reporting issues with accessing Microsoft Azure services, leading to widespread disruption.
At around 2:00 AM GMT, the first wave of service disruptions was reported, primarily affecting Microsoft Azure. As reports of the Microsoft outage began to increase, the support teams at both Microsoft and CrowdStrike sprang into action. By 3:00 AM GMT, Microsoft confirmed that they were experiencing a significant service disruption and had begun an investigation into the root cause.
By 5:00 AM GMT, the issue was traced back to a security update deployed by CrowdStrike, which inadvertently caused a conflict within Microsoft’s infrastructure. Microsoft and CrowdStrike teams collaborated closely, with CrowdStrike providing critical insights that helped narrow down the problematic areas. During this period, Microsoft implemented interim measures to mitigate the impact, such as routing traffic through unaffected servers and issuing temporary fixes to ensure that critical services remained operational.
By 8:00 AM GMT, a comprehensive fix was identified, and Microsoft began rolling out updates to restore services. The deployment of these updates was carried out in phases to ensure stability and prevent further disruptions. By 12:00 PM GMT, most services had been restored, although some localized issues continued to be addressed on a case-by-case basis.
Throughout the day, Microsoft provided regular updates to its user base, detailing the progress of the fix and reassuring customers that the situation was being handled with the utmost priority. By 6:00 PM GMT, the Microsoft outage was officially declared resolved, with all services fully operational. Both Microsoft and CrowdStrike committed to a thorough post-mortem analysis to understand what caused the outage and to implement measures to prevent future occurrences.
Impact on Global Services
The Microsoft global outage, triggered by issues with CrowdStrike, had extensive repercussions on a broad spectrum of Microsoft services, including Azure, Office 365, and other critical platforms. This disruption was not confined to a single geographical location but rather had a worldwide effect, severely impacting businesses and individual users alike.
Azure, Microsoft’s cloud computing service, experienced significant downtime during the outage. This caused substantial operational delays for companies relying on Azure for their daily operations, ranging from small businesses to large enterprises. Essential services like virtual machines, databases, and storage were inaccessible, leading to interruptions in service delivery and business continuity. Reports from various sectors, including healthcare, finance, and retail, highlighted the operational chaos and financial losses incurred due to the Azure outage.
Office 365, another cornerstone of Microsoft’s service offerings, also faced substantial disruptions. Companies that depended on Office 365 for email, document management, and collaboration tools found themselves unable to access critical applications like Outlook, SharePoint, and Teams. This outage crippled internal and external communications, leading to missed deadlines, uncoordinated teams, and significant productivity losses. For instance, a multinational corporation reported that their entire workforce was rendered non-operational for several hours, causing a ripple effect on project timelines and customer support services.
The educational sector was not immune to the effects of the Microsoft outage. Many educational institutions that had adopted Office 365 for remote learning and administrative tasks faced substantial hurdles. Online classes were abruptly halted, and access to essential educational resources was restricted, causing disruptions in academic schedules and student learning experiences.
Individual users also bore the brunt of the outage. Personal accounts tied to Microsoft services experienced lockouts, resulting in loss of access to emails, cloud-stored documents, and other critical personal data. Users took to social media platforms to express their frustration and seek assistance, highlighting the pervasive impact of the outage on daily activities and personal productivity.
Overall, the Microsoft global outage caused by CrowdStrike underscored the dependence of businesses and individuals on Microsoft’s ecosystem. The widespread impact on various services and the real-world examples of disruptions serve as a stark reminder of the critical nature of reliable cloud and communication services in today’s interconnected world.
Response and Communication
During the Microsoft global outage, the response strategies employed by both Microsoft and CrowdStrike were critical in managing the crisis. Both companies recognized the importance of clear and timely communication to mitigate the impact on their users. Microsoft, being the primary service provider affected, took the lead in addressing the situation.
Microsoft’s initial response involved issuing an official statement outlining the scope and nature of the outage. This statement was promptly published on their official website and distributed through various media channels, ensuring maximum reach. The company also utilized its social media platforms, including Twitter and LinkedIn, to provide real-time updates. These updates included information on the progress of the investigation, estimated time for resolution, and any interim measures users could take. By maintaining a consistent flow of information, Microsoft aimed to reassure users that the situation was under control.
CrowdStrike, being implicated in the incident, also took swift action to communicate with its stakeholders. The cybersecurity firm released a detailed explanation of their involvement and the steps they were taking to assist Microsoft in resolving the issue. Like Microsoft, CrowdStrike leveraged social media and their official blog to keep users informed. They also emphasized their commitment to transparency and cooperation in addressing the outage.
Both companies established dedicated support channels to handle user inquiries and provide technical assistance. Microsoft’s support team was available 24/7 through various mediums, including phone, email, and live chat, to assist users experiencing disruptions. CrowdStrike’s customer support also ramped up efforts to address concerns related to their services.
The collaborative response between Microsoft and CrowdStrike exemplified effective crisis management. By prioritizing clear and consistent communication, both companies were able to maintain user trust and navigate the complexities of the outage. Their efforts highlighted the importance of a robust communication strategy in mitigating the effects of a significant service disruption.
Technical Analysis and Lessons Learned
The recent Microsoft global outage, significantly affecting services like Microsoft Azure, has drawn considerable attention from cybersecurity experts. A comprehensive technical analysis reveals that a primary factor contributing to the outage was a misconfiguration within the CrowdStrike security software. This misconfiguration led to a series of cascading failures, severely disrupting Microsoft’s cloud infrastructure.
Experts point out that the initial trigger was an erroneous update deployed by CrowdStrike’s security platform. This update inadvertently altered critical settings within Microsoft’s network, causing a breakdown in communication between servers. As a result, numerous services, including those essential for major industries like airlines, experienced prolonged downtime. The scale and impact of the outage were unprecedented, prompting immediate investigation and response measures from both Microsoft and CrowdStrike.
From a cybersecurity standpoint, the incident highlights the importance of rigorous testing and validation procedures before deploying updates to production environments. CrowdStrike’s misstep underscores the potential risks associated with insufficiently vetted software changes. To mitigate such risks, experts recommend adopting more stringent update protocols, including comprehensive simulation of real-world scenarios to identify potential failure points.
In response to the outage, Microsoft has implemented several significant changes. Among these, enhanced monitoring systems have been introduced to detect anomalies in real-time, allowing for quicker identification and resolution of issues. Additionally, Microsoft has fortified its incident response strategies, ensuring a more agile and coordinated approach to handle future disruptions. CrowdStrike, on its part, has revised its update deployment process, incorporating additional layers of validation and approval to prevent recurrences.
Lessons learned from the Microsoft outage are manifold. Key takeaways include the critical need for robust cross-organizational communication and the establishment of fail-safes to protect against single points of failure. The incident serves as a stark reminder of the interconnected nature of modern digital ecosystems and the potential ripple effects of a single vulnerability.
Overall, the Microsoft global outage has prompted a reevaluation of cybersecurity practices and preparedness. By learning from this event, both Microsoft and CrowdStrike aim to enhance their resilience, ensuring more reliable service delivery and safeguarding against future disruptions.
Industry and User Reactions
The Microsoft global outage triggered by CrowdStrike’s security measures elicited a wide range of reactions from the tech industry and user community. Industry analysts were quick to weigh in, with many emphasizing the complexity of cloud infrastructure and the inherent risks in third-party integrations. While some experts highlighted the necessity of robust security protocols, others questioned the resilience of Microsoft’s cloud services, suggesting that the Microsoft Azure outage revealed vulnerabilities that need addressing.
Affected businesses, particularly those reliant on Microsoft Azure, voiced considerable frustration. Airlines, for instance, experienced significant operational disruptions, pushing them to question their dependency on a single service provider. The widespread nature of the Microsoft outage had a cascading effect, impacting not only direct users but also customers of businesses that operate on Azure. Feedback from these sectors underscored a demand for greater transparency and quicker response times from Microsoft.
From the user base, the sentiment was mixed. While some users expressed understanding, recognizing the challenges of maintaining global cloud services, others were less forgiving. Social media platforms were abuzz with questions like, “Is Microsoft down?” and “What caused the Microsoft outage?” The incident also spurred conversations around contingency planning, with users advocating for diversified cloud strategies to mitigate such widespread disruptions in the future.
Criticism and praise were directed at both Microsoft and CrowdStrike. Microsoft faced scrutiny for the apparent lack of preparedness and slow communication during the outage. Conversely, CrowdStrike received commendation for its proactive security stance, albeit with some critique regarding the unintended consequences of its actions. Overall, the incident has reignited discussions about balancing security measures with system reliability, urging both companies to refine their approaches.
Future Implications
The Microsoft global outage caused by CrowdStrike has far-reaching implications for the tech industry, particularly in the realm of cybersecurity. This incident underscores the vulnerability even major tech companies face, prompting a reevaluation of current cybersecurity practices. Organizations are likely to scrutinize their security protocols more rigorously and invest in advanced threat detection and mitigation solutions. The outage serves as a stark reminder that no system is infallible, and continuous improvement in cybersecurity measures is paramount.
One significant outcome of this event may be an evolution in the relationship between major tech companies. Collaborative efforts for threat intelligence sharing could become more prevalent, as companies recognize the mutual benefits of a united front against cyber threats. This collaboration could lead to the development of industry-wide standards and protocols, fostering a more resilient tech ecosystem.
Moreover, the trust in cloud services has been somewhat shaken. The Microsoft Azure outage not only affected businesses but also critical sectors like airlines, highlighting the dependency on cloud infrastructure. Companies may start to diversify their cloud strategies, incorporating multi-cloud or hybrid solutions to mitigate the risk of a single point of failure. This diversification aims to enhance operational continuity and reduce the impact of potential future outages.
Regulatory and policy changes are also on the horizon. Governments and regulatory bodies might introduce stricter compliance requirements and oversight for cloud service providers. These regulations could mandate more transparent reporting on security practices and incidents, ensuring that companies adhere to the highest standards of cybersecurity. Additionally, there could be an emphasis on developing more robust incident response frameworks to handle large-scale outages effectively.
Overall, the Microsoft outage has catalyzed a critical assessment of the current state of cybersecurity, cloud service reliability, and regulatory frameworks. The lessons learned from this incident will likely drive significant advancements in these areas, shaping the future landscape of the tech industry.


Post Comment